
При выполнении запроса, как мы знаем, оптимизатор SQL Server исходя из существующих индексов и имеющейся свежей статистики пытается за разумное время найти лучший план запроса, конечно если этот план уже не «сидит» в кэше сервера, и запрос выполняется по этому плану и план сохраняется в кэш сервера. Если план уже построен для этого запроса ранее, то запрос выполняется по существующему плану.
Нам в этой теме интересен следующий момент: Во время компиляции плана запроса, при переборе возможных индексов, если лучшего индекса не нашлось (по мнению сервера), то в плане запроса помечается этот не найденный индекс, и сервер ведет статистику по таким индексам – сколько раз сервер бы воспользовался этим индексом и сколько стоил этот запрос. Эти отсутствующие индексы – missing indexes мы сейчас и разберем, что с ними делать и как с ними работать.
Предлагаю на примере разобраться с отсутствующими индексами. Создадим пару таблиц в нашей, БД на локальном или тестовом сервере:
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'Vasa'),
(2,'Peta'),
(3,'Anna'),
(4,'Ira'),
(5,'Igor')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Сахар', 50),
(2,'Молоко', 80),
(3,'Хлеб', 20),
(4,'Макароны', 40),
(5,'Пиво', 100)
) t (id,product, price) on t.id = c.product_id
go
Структура простая из 2х табличек: продажи где поля идентификатор, дата продажи и продавец и другая таблица – детализация этих продаж, где какие-то товары в этой продаже указаны с ценой и количеством.
Предлагаю посмотреть простой запрос и его план:
select count(*) from orders o join orders_detail d on o.id = d.order_id
where d.cost > 1800
go
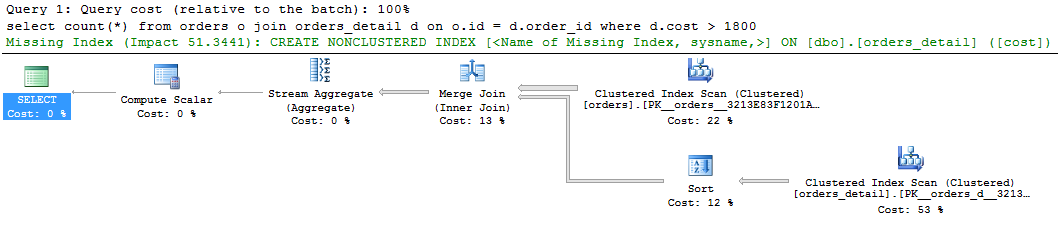
На графическом отображении плана запроса видна подсказка зеленым цветом об отсутствующем индексе, если кликнуть по ней правой кнопкой мыши и выделить «Missing Index Details..» то получим текст предлагаемого индекса, в тексте только лишь убрать комментарии и дать какое-нибудь имя индексу и скрипт готов к выполнению.
Мы не будем строить этот индекс, который дала подсказка в SSMS, а посмотрим будет ли рекомендован индекс этот динамическими представлениями, связанными с отсутствующими индексами. Эти представления:
select * from sys.dm_db_missing_index_group_stats
select * from sys.dm_db_missing_index_details
select * from sys.dm_db_missing_index_groups
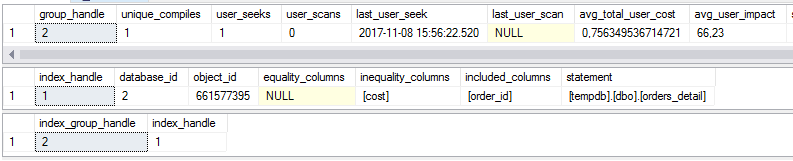
Мы из этого видим, что в 1м представлении у нас есть статистика по отсутствующих индексах, а именно:
-
Сколько бы раз произвелся поиск если бы предложенный индекс существовал?
-
Сколько раз использовалось бы сканирование если бы предложенный индекс существовал.
-
Дата время последней потребности в этом индексе
-
Текущая реальная стоимость плана запроса без предлагаемого индекса.
2е представление это уже тело индекса по сути:
-
База данных
-
Объект/таблица
-
Сортированные колонки
-
Колонки включенные для увеличения покрытия индекса
3е представление - это связь 1го и 2х представлений.
Соответственно, здесь не трудно получить скрипт, который бы из этих динамических представлений сгенерировал скрипт по созданию отсутствующих индексов. Сам скрипт у меня получился таким:
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc
В порядке эффективности индексов выведены отсутствующие индексы. Идеально когда этот резалтсет ничего не возвращает, на нашем примере этот резалтсет возвратит минимум один индекс:

Когда совсем лень или некогда разбираться с тормозами у пары заказчиков я выполнял этот запрос, копировал первую колонку и выполнял на сервере. После этого тормоза уходили ?.
Я рекомендую осознано подходить к полученной информации с этими индексами. Например, если рекомендовать ситема будет следующие индексы:
create index ix_01 on tbl1 (a,b) include (c)
create index ix_02 on tbl1 (a,b) include (d)
create index ix_03 on tbl1 (a)
И эти индексы используются для поиска/seek, то вполне очевидно, что логичнее заменить эти индексы на один который покроет все 3 предложенных:
create index ix_1 on tbl1 (a,b) include (c,d)
Т.е. как минимум ревью предлагаемых индексов перед тем как их накатить на боевой сервер. Хотя…. Повторюсь, например на сервер TFS я накатывал потерянные индексы и общая производительность выростала, а время на такую оптимизацию затрачено минимум. Хотя, впоследствии с ТФС 2015 на ТФС 2017 я столкнулся с тем что обновление не проходило из-за новых индексов. Но их легко можно найти были по маске
select * from sys.indexes where name like 'ix[_]2017%'