
Постановка задачи
Задачу необходимо решить на SQL Server 2014 Enterprise Edition (x64).
В фирме есть определенное количество складов (по факту - много). На каждом складе ежедневно производится по нескольку тысяч отгрузок и приемок продуктов. Есть таблица движений товаров на складе - приход/расход. Необходимо реализовать:
- Расчет баланса на выбранную дату и время (с точностью до часа) по всем/любому складам по каждому продукту.
- Для аналитики необходимо создать объект (функцию, таблицу, представление), с помощью которого за выбранный диапазон дат вывести по всем складам и продуктам данные исходной таблицы и дополнительную расчетную колонку — остаток на складе позиции.
- Указанные расчеты предполагаются выполняться по расписанию с разными диапазонами дат и должны работать в приемлемое время. Т.е. если необходимо вывести таблицу с остатками за последний час или день, то время выполнения должно быть максимально быстрым, равно как и если необходимо вывести за последние 3 года эти же данные, для последующей загрузки в аналитическую базу данных.
Технические подробности. Сама таблица:
create table dbo.Turnover ( id int identity primary key, dt datetime not null, ProductID int not null, StorehouseID int not null, Operation smallint not null check (Operation in (-1,1)), -- +1 приход на склад, -1 расход со склада Quantity numeric(20,2) not null, Cost money not null )
Dt — Дата время поступления/списания на/со склада.
ProductID — Продукт
StorehouseID — склад
Operation — 2 значения приход или расход
Quantity — количество продукта на складе. Может быть вещественным если продукт не в штуках, а, например, в килограммах.
Cost — стоимость партии продукта.
Исследование задачи
Для начала создадим заполненную таблицу. Для того что бы вы могли вместе со мной тестировать и смотреть получившиеся результаты, предлагаю создать и заполнить таблицу dbo.Turnover скриптом:
if object_id('dbo.Turnover','U') is not null drop table dbo.Turnover;
go
with times as
(
select 1 id
union all
select id+1
from times
where id < 10*365*24*60 -- 10 лет * 365 дней * 24 часа * 60 минут = столько минут в 10 годах
)
, storehouse as
(
select 1 id
union all
select id+1
from storehouse
where id < 100 -- количество складов
)
select
identity(int,1,1) id,
dateadd(minute, t.id, convert(datetime,'20060101',120)) dt,
1+abs(convert(int,convert(binary(4),newid()))%1000) ProductID, -- 1000 - количество разных продуктов
s.id StorehouseID,
case when abs(convert(int,convert(binary(4),newid()))%3) in (0,1) then 1 else -1 end Operation, -- возможный приход и расход; случайным образом сделаем из 3х вариантов 2 прихода 1 расход
1+abs(convert(int,convert(binary(4),newid()))%100) Quantity
into dbo.Turnover
from times t cross join storehouse s
option(maxrecursion 0);
go
--- 15 min
alter table dbo.Turnover alter column id int not null
go
alter table dbo.Turnover add constraint pk_turnover primary key (id) with(data_compression=page)
go
-- 6 min
У меня этот скрипт на ПК с SSD диском выполнялся порядка 22 минуты, и размер таблицы занял около 8Гб на жестком диске. Вы можете уменьшить количество лет и количество складов для того чтобы сократить время создания и заполнения таблицы. Но какой-то неплохой объем для оценки планов запросов рекомендую оставить, хотя бы 1-2 гигабайта.
Теперь сгруппируем данные до часа. Далее нам нужно сгруппировать суммы по продуктам на складе за исследуемый период времени, в нашей постановке задачи - это один час (можно до минуты, до 15 минут, дня. Но очевидно до миллисекунд вряд ли кому понадобится отчетность). Для сравнений в сессии (окне) где выполняем наши запросы выполним команду — set statistics time on;.
Выполняем сами запросы и смотрим планы запросов:
select top(1000) convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа ProductID, StorehouseID, sum(Operation*Quantity) as Quantity from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+':00',120), ProductID, StorehouseID

Стоимость запроса — 12406
(строк обработано: 1000)
Время работы SQL Server: Время ЦП = 2096594 мс, затраченное время = 321797 мс.
Если мы сделаем результирующий запрос с балансом, который считается нарастающим итогом от нашего количества, то запрос и план запроса будут следующими:
select top(1000) convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа ProductID, StorehouseID, sum(Operation*Quantity) as Quantity, sum(sum(Operation*Quantity)) over ( partition by StorehouseID, ProductID order by convert(datetime,convert(varchar(13),dt,120)+':00',120) ) as Balance from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+':00',120), ProductID, StorehouseID
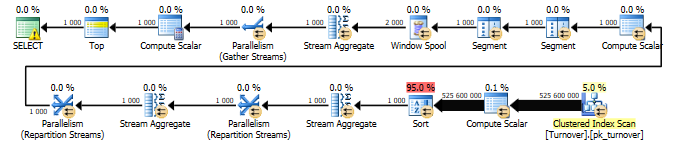
Стоимость запроса — 19329
(строк обработано: 1000)
Время работы SQL Server: Время ЦП = 2413155 мс, затраченное время = 344631 мс.
Оптимизация группировки
Здесь все достаточно просто. Сам запрос без нарастающего итога можно оптимизировать материализованным представлением (index view). Для построения материализованного представления то, что суммируется, не должно иметь значение NULL - у нас суммируются sum(Operation*Quantity), или каждое поле сделать NOT NULL или добавить isnull/coalesce в выражение. Предлагаю создать материализованное представление.
create view dbo.TurnoverHour with schemabinding as select convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа ProductID, StorehouseID, sum(isnull(Operation*Quantity,0)) as Quantity, count_big(*) qty from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+':00',120), ProductID, StorehouseID go
Теперь нужно построить по нему кластерный индекс. В индексе порядок полей укажем так же, как и в группировке (для группировки порядок не важен, важно что бы все поля группировки были в индексе) и нарастающем итоге (здесь важен порядок — сначала то, что в partition by, затем то, что в order by):
create unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt) with (data_compression=page) --- 19 min
Теперь после построения кластерного индекса мы можем заново выполнить запросы, изменив агрегацию суммы как в представлении:
select top(1000) convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа ProductID, StorehouseID, sum(isnull(Operation*Quantity,0)) as Quantity from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+':00',120), ProductID, StorehouseID select top(1000) convert(datetime,convert(varchar(13),dt,120)+':00',120) as dt, -- округляем до часа ProductID, StorehouseID, sum(isnull(Operation*Quantity,0)) as Quantity, sum(sum(isnull(Operation*Quantity,0))) over ( partition by StorehouseID, ProductID order by convert(datetime,convert(varchar(13),dt,120)+':00',120) ) as Balance from dbo.Turnover group by convert(datetime,convert(varchar(13),dt,120)+':00',120), ProductID, StorehouseID
Планы запросов стали:
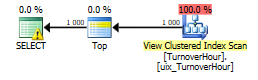
Стоимость 0.008
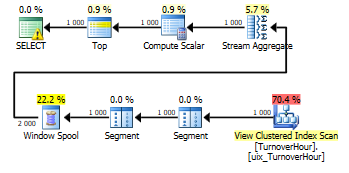
Стоимость 0.01
Время работы SQL Server: Время ЦП = 31 мс, затраченное время = 116 мс. (строк обработано: 1000) Время работы SQL Server: Время ЦП = 0 мс, затраченное время = 151 мс.
Итого, мы видим, что с материализованным представлением запрос сканирует не таблицу, группируя данные, а кластерный индекс, в котором уже все сгруппировано. И, соответственно, время выполнения сократилось с 321797 миллисекунд до 116 мс., т.е. в 2774 раза.
На этом бы можно было бы и закончить нашу оптимизацию, если бы не тот факт, что нам нужна зачастую не вся таблица (представление), а ее часть за выбранный диапазон.
Промежуточные балансы
В итоге нам нужно быстрое выполнение следующего запроса:
set dateformat ymd; declare @start datetime = '2015-01-02', @finish datetime = '2015-01-03' select * from ( select dt, StorehouseID, ProductId, Quantity, sum(Quantity) over ( partition by StorehouseID, ProductID order by dt ) as Balance from dbo.TurnoverHour with(noexpand) where dt <= @finish ) as tmp where dt >= @start
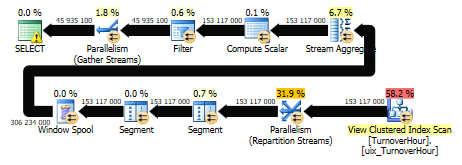
Стоимость плана = 3103. А представьте, что было бы, если бы запрос выполнялся не по материализованному представлению, а по самой таблице.
Вывод данных материализованного представления и баланса по каждому продукту на складе на дату со временем, округленную до часа. Чтобы посчитать баланс — необходимо с самого начала (с нулевого баланса) просуммировать все количества до указанной последней даты (@finish), а после уже в просуммированном resultset отсечь данные, которые больше параметра @start.
Здесь, очевидно, помогут промежуточные рассчитанные балансы. Например, на 1-е число каждого месяца или на каждое воскресенье. Имея такие балансы, задача сводится к тому, что нужно будет суммировать ранее рассчитанные балансы и рассчитать баланс не от начала, а от последней рассчитанной даты. Для экспериментов и сравнений построим дополнительный не кластерный индекс по дате:
create index ix_dt on dbo.TurnoverHour (dt) include (Quantity) with(data_compression=page); --7 min И наш запрос будет вида: set dateformat ymd; declare @start datetime = '2015-01-02', @finish datetime = '2015-01-03' declare @start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120) select * from ( select dt, StorehouseID, ProductId, Quantity, sum(Quantity) over ( partition by StorehouseID, ProductID order by dt ) as Balance from dbo.TurnoverHour with(noexpand) where dt between @start_month and @finish ) as tmp where dt >= @start order by StorehouseID, ProductID, dt
Вообще, этот запрос имея даже индекс по дате, полностью покрывающий все затрагиваемые в запросе поля, выберет наш кластерный индекс и сканирование, а не поиск по дате с последующей сортировкой. Предлагаю выполнить следующие 2 запроса и сравнить, что у нас получилось. Далее проанализируем, что все-таки лучше:
set dateformat ymd; declare @start datetime = '2015-01-02', @finish datetime = '2015-01-03' declare @start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120) select * from ( select dt, StorehouseID, ProductId, Quantity, sum(Quantity) over ( partition by StorehouseID, ProductID order by dt ) as Balance from dbo.TurnoverHour with(noexpand) where dt between @start_month and @finish ) as tmp where dt >= @start order by StorehouseID, ProductID, dt select * from ( select dt, StorehouseID, ProductId, Quantity, sum(Quantity) over ( partition by StorehouseID, ProductID order by dt ) as Balance from dbo.TurnoverHour with(noexpand,index=ix_dt) where dt between @start_month and @finish ) as tmp where dt >= @start order by StorehouseID, ProductID, dt
Время работы SQL Server: Время ЦП = 33860 мс, затраченное время = 24247 мс. (строк обработано: 145608) (строк обработано: 1) Время работы SQL Server: Время ЦП = 6374 мс, затраченное время = 1718 мс. Время синтаксического анализа и компиляции SQL Server: время ЦП = 0 мс, истекшее время = 0 мс.
Из времени выполнения видно, что индекс по дате выполняется значительно быстрее. Но планы запросов в сравнении выглядят следующим образом:

Стоимость первого запроса с автоматически выбранным кластерным индексом = 2752, а вот стоимость запроса с индексом по дате запроса = 3119.
Как бы то ни было, здесь нам требуется от индекса две задачи: сортировка и выборка диапазона. Одним индексом из имеющихся нам эту задачу не решить. В данном примере диапазон данных всего за 1 день, но если будет период больше, например, за 2 месяца, то поиск по индексу будет однозначно не эффективен из-за расходов на сортировку.
Здесь из видимых оптимальных решений я вижу:
- Создать вычисляемое поле Год-Месяц и создать индекс (Год-Месяц, остальные поля кластерного индекса). В условии where dt between @start_month and @finish заменить на Год-Месяц=@месяц, и после этого уже применить фильтр на нужные даты.
- Создать фильтрованные индексы — сам индекс как кластерный, но фильтр по дате, за нужный месяц. И таких индексов сделать столько, сколько месяцев. Идея близка к решению, но здесь, если диапазон условий будет из двух фильтрованных индексов, потребуется соединение и в дальнейшем все равно сортировка неизбежна.
- Секционируем кластерный индекс так, чтобы в каждой секции были данные только за один месяц.
В проекте в итоге я сделал 3-й вариант. Секционирование кластерного индекса материализованного представления. И если выборка идет за промежуток времени одного месяца, то оптимизатор затрагивает только одну секцию, делая ее сканирование без сортировки. А отсечение неиспользуемых данных происходит на уровне отсечения неиспользуемых секций. Если поиск с 10 по 20 число у нас не идет точный поиск этих дат, а поиск данных с 1го по последний день месяца, далее сканирование этого диапазона в отсортированном индексе с фильтрацией во время сканирования по выставленным датам.
Секционируем кластерный индекс представления. Прежде всего удалим из вьюхи все индексы:
drop index ix_dt on dbo.TurnoverHour;
drop index uix_TurnoverHour on dbo.TurnoverHour;
И создадим функцию и схему секционирования:
set dateformat ymd; create partition function pf_TurnoverHour(datetime) as range right for values ( '2006-01-01', '2006-02-01', '2006-03-01', '2006-04-01', '2006-05-01', '2006-06-01', '2006-07-01', '2006-08-01', '2006-09-01', '2006-10-01', '2006-11-01', '2006-12-01', '2007-01-01', '2007-02-01', '2007-03-01', '2007-04-01', '2007-05-01', '2007-06-01', '2007-07-01', '2007-08-01', '2007-09-01', '2007-10-01', '2007-11-01', '2007-12-01', '2008-01-01', '2008-02-01', '2008-03-01', '2008-04-01', '2008-05-01', '2008-06-01', '2008-07-01', '2008-08-01', '2008-09-01', '2008-10-01', '2008-11-01', '2008-12-01', '2009-01-01', '2009-02-01', '2009-03-01', '2009-04-01', '2009-05-01', '2009-06-01', '2009-07-01', '2009-08-01', '2009-09-01', '2009-10-01', '2009-11-01', '2009-12-01', '2010-01-01', '2010-02-01', '2010-03-01', '2010-04-01', '2010-05-01', '2010-06-01', '2010-07-01', '2010-08-01', '2010-09-01', '2010-10-01', '2010-11-01', '2010-12-01', '2011-01-01', '2011-02-01', '2011-03-01', '2011-04-01', '2011-05-01', '2011-06-01', '2011-07-01', '2011-08-01', '2011-09-01', '2011-10-01', '2011-11-01', '2011-12-01', '2012-01-01', '2012-02-01', '2012-03-01', '2012-04-01', '2012-05-01', '2012-06-01', '2012-07-01', '2012-08-01', '2012-09-01', '2012-10-01', '2012-11-01', '2012-12-01', '2013-01-01', '2013-02-01', '2013-03-01', '2013-04-01', '2013-05-01', '2013-06-01', '2013-07-01', '2013-08-01', '2013-09-01', '2013-10-01', '2013-11-01', '2013-12-01', '2014-01-01', '2014-02-01', '2014-03-01', '2014-04-01', '2014-05-01', '2014-06-01', '2014-07-01', '2014-08-01', '2014-09-01', '2014-10-01', '2014-11-01', '2014-12-01', '2015-01-01', '2015-02-01', '2015-03-01', '2015-04-01', '2015-05-01', '2015-06-01', '2015-07-01', '2015-08-01', '2015-09-01', '2015-10-01', '2015-11-01', '2015-12-01', '2016-01-01', '2016-02-01', '2016-03-01', '2016-04-01', '2016-05-01', '2016-06-01', '2016-07-01', '2016-08-01', '2016-09-01', '2016-10-01', '2016-11-01', '2016-12-01', '2017-01-01', '2017-02-01', '2017-03-01', '2017-04-01', '2017-05-01', '2017-06-01', '2017-07-01', '2017-08-01', '2017-09-01', '2017-10-01', '2017-11-01', '2017-12-01', '2018-01-01', '2018-02-01', '2018-03-01', '2018-04-01', '2018-05-01', '2018-06-01', '2018-07-01', '2018-08-01', '2018-09-01', '2018-10-01', '2018-11-01', '2018-12-01', '2019-01-01', '2019-02-01', '2019-03-01', '2019-04-01', '2019-05-01', '2019-06-01', '2019-07-01', '2019-08-01', '2019-09-01', '2019-10-01', '2019-11-01', '2019-12-01'); go create partition scheme ps_TurnoverHour as partition pf_TurnoverHour all to ([primary]); go Ну и уже известный нам кластерный индекс только в созданной схеме секционирования: create unique clustered index uix_TurnoverHour on dbo.TurnoverHour (StorehouseID, ProductID, dt) with (data_compression=page) on ps_TurnoverHour(dt); --- 19 min И теперь посмотрим, что у нас получилось. Сам запрос: set dateformat ymd; declare @start datetime = '2015-01-02', @finish datetime = '2015-01-03' declare @start_month datetime = convert(datetime,convert(varchar(9),@start,120)+'1',120) select * from ( select dt, StorehouseID, ProductId, Quantity, sum(Quantity) over ( partition by StorehouseID, ProductID order by dt ) as Balance from dbo.TurnoverHour with(noexpand) where dt between @start_month and @finish ) as tmp where dt >= @start order by StorehouseID, ProductID, dt option(recompile);
Время работы SQL Server:
Время ЦП = 7860 мс, затраченное время = 1725 мс.
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 0 мс, истекшее время = 0 мс.
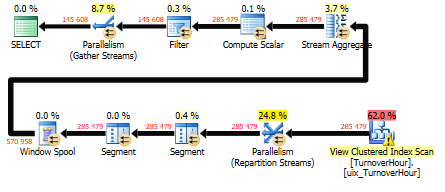
Стоимость плана запроса = 9.4
В реультате данные в одной секции выбираются и сканируются по кластерному индексу достаточно быстро. Здесь следует добавить то, что когда запрос параметризирован, возникает неприятный эффект parameter sniffing, который можно убрать с помощью option(recompile).